DMDSpeech:
Distilled Diffusion Model Surpassing The Teacher in Zero-shot Speech Synthesis via Direct Metric Optimization
Abstract
Diffusion models have demonstrated significant potential in speech synthesis tasks, including text-to-speech (TTS) and voice cloning. However, their iterative denoising processes are inefficient and hinder the application of end-to-end optimization with perceptual metrics. In this paper, we propose a novel method of distilling TTS diffusion models with direct end-to-end evaluation metric optimization, achieving state-of-the-art performance. By incorporating Connectionist Temporal Classification (CTC) loss and Speaker Verification (SV) loss, our approach optimizes perceptual evaluation metrics, leading to notable improvements in word error rate and speaker similarity. Our experiments show that DMDSpeech consistently surpasses prior state-of-the-art models in both naturalness and speaker similarity while being significantly faster. Moreover, our synthetic speech has a higher level of voice similarity to the prompt than the ground truth in both human evaluation and objective speaker similarity metric. This work highlights the potential of direct metric optimization in speech synthesis, allowing models to better align with human auditory preferences.
Model Overview
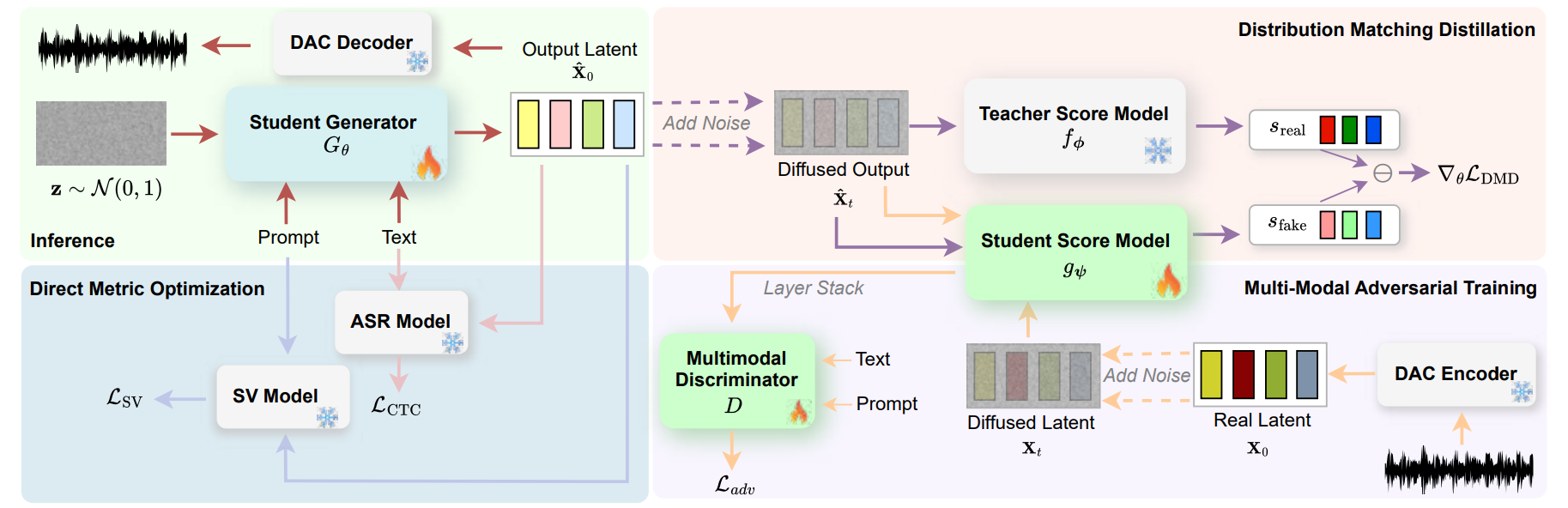
The framework consists of inference and three main components for training: (1) Inference (upper left): A few-step distilled generator synthesizes speech directly from noise, conditioned on the text and speaker prompt (red arrow). (2) Distribution Matching Distillation (upper right): Gradient computation for DMD loss where the student score model matches the teacher score model to align the distribution of student generator with the teacher distribution (purple arrow). (3) Multi-Modal Adversarial Training (lower right): The discriminator uses stacked features from the student score model to distinguish between real and synthesized noisy latents conditioned on both text and prompt (yellow arrows). (4) Direct Metric Optimization (lower left): Direct metric optimization for word error rate (WER) via CTC loss (pink arrow) and speaker embedding cosine similarity (SIM) via SV loss (blue arrow).
Comparison to Previous SOTA
This section contain samples sourced from other SOTA model demo page for a comparison with our model. For each model, we compare different aspects. All samples are downsampled to 16 kHz for fair comparison.
Our model was only trained on LibriLight dataset and has not seen any of the prompt voice below.
Comparison to NaturalSpeech 3 and DiTTo-TTS (Emotions)
We compare our model to NaturalSpeech 3 and DiTTo-TTS for emotional speech. The samples of NaturalSpeech 3, DiTTo-TTS, prompts, and texts are sourced from DiTTo-TTS demo page. The text synthesized is "why fades the lotus of the water" from LibriSpeech test set.
| Emotion | Prompt | DMDSpeech | DiTTo-TTS | NaturalSpeech 3 |
|---|---|---|---|---|
| Neutral | ||||
| Calm | ||||
| Sad | ||||
| Angry | ||||
| Happy | ||||
| Surprised |
Comparison to DiTTo-TTS (Voice Clone)
We compare our model to DiTTo-TTS for cloning the voice of vairous fictional characters. The samples of DiTTo-TTS, prompts, and texts are sourced from its official demo page.
| Character | Prompt | DMDSpeech | DiTTo-TTS |
|---|---|---|---|
| Rick (Rick and Morty) | |||
| SpongeBob | |||
| Optimus Prime | |||
| Morty (Rick and Morty) |
Comparison to Vall-E 2 (Continuation)
We compare our model to Vall-E 2 for both cross-sentence synthesis and sentence continuation. Due to policy restriction, we were unable to obtain samples from the authors and conduct subjective evaluation in our study. The comparison here is for reference purpose only, and samples are taken from its official demo page. All samples of Vall-E 2 are with GroupSize=1 as it is shown to have the best performance in the paper.
| Text | Prompt (Prefix/Ref) | DMDSpeech | Vall-E 2 |
|---|---|---|---|
| They moved thereafter cautiously about the hut, groping before and about them to find something to show that Warrenton had fulfilled his mission. |
|
|
|
| Number ten, fresh nelly is waiting on you, good night husband. |
|
|
|
| Instead of shoes, the old man wore boots with turnover tops and his blue coat had wide cuffs of gold braid. |
|
|
|
Comparison to StyleTTS 2 (Long-Form Generation)
We compare our model to StyleTTS 2 for long-form generation. Our model with only 7 second of prompt speech can perform similarly well as SOTA single-speaker model trained on this particular speaker with 24 hours of data. The sample is taken from its official demo page.
| Prompt for DMDSpeech | DMDSpeech | StyleTTS 2 |
|---|---|---|
In-the-Wild Samples
This section contain samples sourced in the wild to show our model has great robustness and generalizability to various cases.
Our model was only trained on LibriLight dataset and has not seen any of the prompt voice or language below.
| Cases | Prompt | Text | DMDSpeech |
|---|---|---|---|
Noisy Recording (Sports Commentator) |
And here is our DMD Speech, and, oh my god! It can generalize to noisy commentating voice too, what a surprise! | ||
Screaming Voice (Death Metal Growl) |
This is DMD. It gets your voice deep. Why can it do metal growl? Why, can it do metal growl? | ||
Processed Voice (StarCraft Protoss Advisor) |
Executor, your model requires more distillation. Distillation complete. In taro DMD! | ||
Non-English (Speech-to-Speech Translation) |
No. You only need to do it for 3 hours a day from Monday to Friday. |
Zero-Shot TTS (LibriSpeech)
This section contain audio samples from our models and all baseline models we compared in our paper on the LibriSpeech test-clean dataset. Samples from other models are taken from StyleTTS-ZS demo page.
| Text |
Their piety would be like their names, like their faces, like their clothes, and it was idle for him to tell himself that their humble and contrite hearts it might be paid a far-richer tribute of devotion than his had ever been. A gift tenfold more acceptable than his elaborate adoration. |
The air and the earth are curiously mated and intermingled as if the one were the breath of the other. |
His death in this conjuncture was a public misfortune. |
Indeed, there were only one or two strangers who could be admitted among the sisters without producing the same result. |
It is this that is of interest to theory of knowledge. |
I had always known him to be restless in his manner, but on this particular occasion he was in such a state of uncontrollable agitation that it was clear something very unusual had occurred. |
For a few miles, she followed the line hitherto presumably occupied by the coast of Algeria, but no land appeared to the south. |
For if he's anywhere on the farm, we can send for him in a minute. |
|---|---|---|---|---|---|---|---|---|
| Prompt | ||||||||
| DMDSpeech (Ours) | ||||||||
| NaturalSpeech 3 | ||||||||
| StyleTTS-ZS | ||||||||
| DiTTo-TTS | ||||||||
| CLaM-TTS | ||||||||
| VoiceCraft | ||||||||
| XTTS | ||||||||
| Ground Truth |
* please scroll horizontally to see more samples (8 samples total).
Ablation Study
This section contain audio samples for our ablation study. The ablation of each model is as follows:
- DMDSpeech (N=4): Our proposed model, DMDSpeech with 4 steps of sampling.
- Teacher (N=128): The teacher diffusion model with 128 steps of sampling.
- DMD 2 Only (N=1): The model trained with DMD 2 only with 1 step of sampling.
- DMD 2 Only (N=4): The model trained with DMD 2 only with 4 steps of sampling.
- SV loss Only: The model trained with DMD 2 with 4 steps of sampling plus SV loss (i.e., DMDSpeech without CTC loss).
- CTC loss Only: The model trained with DMD 2 with 4 steps of sampling plus CTC loss (i.e., DMDSpeech without SV loss).
- Batch size 16: DMDSpeech trained with a batch size of 16 instead of 96.
| Text |
Seeing that I am so fine, I may as well go and visit the King. |
Nine thousand years have elapsed since she founded yours, and eight thousand since she founded ours, as our annals record. |
The fact that a man can recite a poem does not show that he remembers any previous occasion on which he has recited or read it. |
See that your lives be in nothing worse than a boy's climbing for his entangled kite. |
It is evident, therefore, that the present trend of the development is in the direction of heightening the utility of conspicuous consumption as compared with leisure. |
Horse sense a degree of wisdom that keeps one from betting on the races. |
And though I have grown serene and strong since then, I think that God has willed a still renewable fear. |
Cried the young ladies, and they quickly put out the fire. |
|---|---|---|---|---|---|---|---|---|
| Prompt | ||||||||
| DMDSpeech (N=4) | ||||||||
| Teacher (N=128) | ||||||||
| DMD 2 Only (N=1) | ||||||||
| DMD 2 Only (N=4) | ||||||||
| SV loss Only | ||||||||
| CTC loss Only | ||||||||
| Batch zize 16 |
* please scroll horizontally to see more samples (8 samples total).